자연어 처리(natural language processing)는 인간의 언어 현상을 기계적으로 분석해서 컴퓨터가 이해할 수 있는 형태로 만드는 자연 언어 이해 혹은 그러한 형태를 다시 인간이 이해할 수 있는 언어로 표현하는 제반 기술을 의미한다. (위키피디아)
간단하게 말하면, 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일 이라고 생각하면 될 것 같다.
텍스트
기계학습 모델을 만들기 위해서는 데이터를 모델에 맞게 변형시켜 주어야 한다. 알고리즘에서 텍스트를 그대로 받아들일수 없기 때문에 받아들일 수 있는 어떤 숫자값으로 변환을 해주어야 한다. 하지만 텍스트는 일단 언어가 제각기 다르기 떄문에 텍스트 자체를 어떻게 숫자화 할지 부터 시작해야한다.
그럼 어떤 방법들이 있는지 살펴보자.
BOW(bag of words)
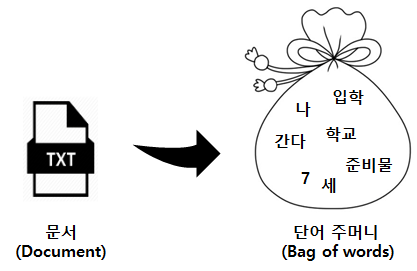
BOW(Bag of words)는 텍스트 데이터를 표현하는 방법 중 하나로 가장 간단하지만 효과적이라 기계학습에서 널리 쓰이는 방법이다. BOW는 텍스트의 구조와 상관없이 단어들을 담는 가방(Bag)으로 생각하면 된다.
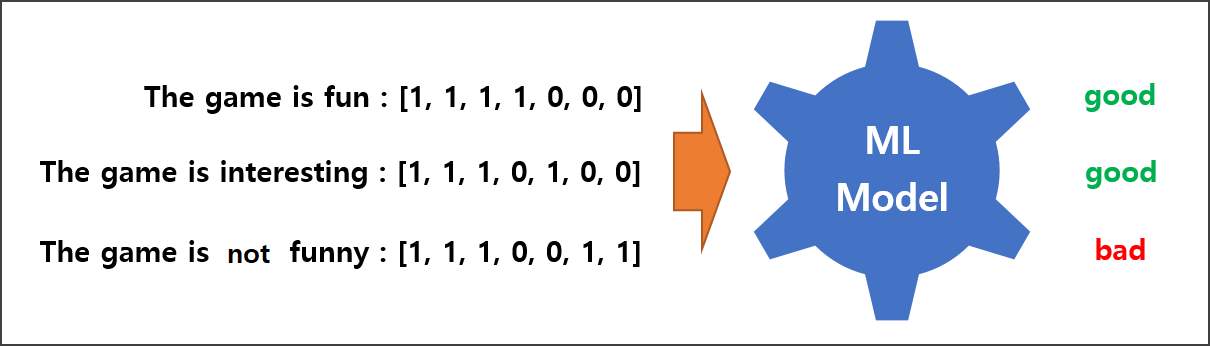
The game is fun
The game is interesting
The game is not funny세 문장에서 나타나는 단아들을 모으고 세 문장을 각각 binary vector로 표현하는 것이 BOW이다. 각각의 문장을 binary vector로 표현하면 다음과 같다.
| the | game | is | fun | interesting | not | funny |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 0 | 0 | 0 |
The game is fun : [1, 1, 1, 1, 0, 0, 0]
| the | game | is | fun | interesting | not | funny |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 1 | 0 | 0 |
The game is interesting : [1, 1, 1, 0, 1, 0, 0]
| the | game | is | fun | interesting | not | funny |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 1 | 1 |
The game is not funny : [1, 1, 1, 0, 0, 1, 1]
만약 이 가방에 들어있지 않는 단어가 포함된 문장이 있어도 BOW는 그 없는 단어는 제외하고 있는 단어만을 가지고 벡터로 만들 것이다.
그럼 이 수치로 표현된 값을 어떻게 활용할까?
머신러닝 모델에 입력값으로 사용할 수도 있디만 단순히 계산만으로 문장간의 유사도(Sentence similarity)를 알 수도 있다.
the game is fun 과 The game is interesting 문장의 유사도를 구해보자.
| 문장 | 벡터값 |
|---|---|
| the game is fun | [1, 1, 1, 1, 0, 0, 0] |
| The game is interesting | [1, 1, 1, 0, 1, 0, 0] |
유사도 = (1x1) + (1x1) + (1x1) + (1x0) + (0x1) + (0x0) + (0x0) = 3
또한 수치로 표한된 값을 이용해 기계학습 모델에 입력값으로 사용할 수가 있다. 문장에 대한 감성분석을 해주는 모델이 있다면, 벡터화된 값을 모델에 입력값으로 사용할 수 있고 모델은 우리가 원하는 Good 또는 Bad의 결과를 출력해 줄 수 있다.
하지만 BOW는 몇 가지 단점이 있다.
- Sparsity
실제 사전에는 100만개가 넘는 단어들이 있을 수도 있다. 그렇게 되면 벡터의 차원이 100만개가 넘어가기 때문에 실제 문장하나를 표현할 때 대부분의 값이 0이고 그외의 값들은 상당히 적을 것이다. 결국 학습량이 많아지고 컴퓨터 자원도 상당히 많이 사용하게 된다.
(the game is fun [1,1,1,1,0,0,0,0,0,0,0,,,,,,0,0,0,0,0]) - 빈번한 단어는 더 많은 힘을 가진다.
많이 출현한 단어는 힘이 세진다. 만약 의미없는 단어들이 많이 사용 되었다면 우리가 원하는 결과를 얻기는 어려울 것이다. - Out of vocabulary
오타, 줄임말 등의 단어들이 포함되면 굉장히 난감해진다.^^; - 단어의 순서가 무시됨
단어의 출현 횟수만 셀수 있고 단어의 순서는 완전히 무시 된다. 단어의 순서가 무시된다는 것은 다른 의미를 가진 문장이 동일한 결과로 해석될 수 있다는 것이다.
전혀 반대의 의미를 가진 두 문장을 보자.

두 문장은 의미가 전혀 반대이지만 BOW를 이용해 처리한다면, 동일한 결과를 반환하게 될 것이다. 이런 단점을 보완하기 위해 좀더 개선된 n-gram이란 것이 있다. BOW는 하나의 토큰을 사용하지만 n-gram은 n개의 토큰을 사용하여 어느정도 단어의 순서를 반영 결과에 반영해 준다.
N-Gram
BOW를 조금 더 개선하여 단어 하나만을 보는 것이 아니라 주변의 n개 단어를 뭉쳐서 보는 것이다. 뭉쳐진 n개의 단어들을 gram이라고 한다.
단어 개수에 따라 부르는 명칭이 다른데 2개의 단어를 묶어서 사용하면 bi-gram, 3개면 tri-gram이라고 부른다.
(1-gram은 uni-gram이라고 한다.)
다음 문장을 bi-gram를 사용하여 처리 한다면,
"home run" 과 "run home"
bag of words : [home, run] , [run, home]
bi-gram : [home run], [run home]
BOW를 사용한다면 두 문장은 같은 백터의 값을 갖게 되겠지만 bi-gram을 사용하면 2개를 뭉쳐서 사용하므로 어느정도의 순서가 보장되는 효과를 볼수 있게 되어 다른 결과 값을 가지게 될 것이다.
이런 특성을 이용해 n-gram은 다음 단어 예측하거나 어떤 단어를 입력 했을때 오타를 발견하고 다른 단어를 추천해 주는데 활용할 수 있다.
텍스트 전처리 (Preprocessing)
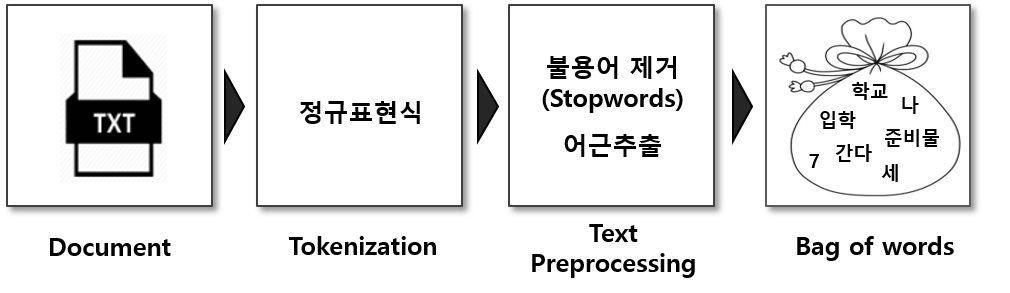
BOW나 n-gram이나 모두 많이 쓰이지만 가장 중요한 것은 단어의 전처리가 확실해야 한다는 것이다. 이 글에서는 설명을 위해 간단한 문장만을 사용하여 크게 신경을 쓸 필요는 없겠지만, 자연어 처리를 하다보면 다양한 케이스의 문장들을 접하게 될 것이며 이런 문장들을 토큰화하고 불필요한 단어들은 제거하고 같은 의미의 단어들은 치환하는 등의 고단한 작업 들을 해야 할 것이다. 하지만 다행인 것은 이런 전처리 작업들을 편하게 할 수 있도록 도와주는 좋은 라이브러리들이 있다.
다음 포스팅에서는 전처리에 대해 자세히 살펴보도록 하겠다...