인공지능, 머신러닝, 딥러닝에 대해 자세히는모르지만 부분 한번쯤을 어보았을 것이다. 분명 3가지는 차이가 있으며 어떤 차이가 있는지부터 알아보자.
머신러닝은 말 그데로 "기계가 학습?" 그럼 인공지능과 딥러닝은? 마찬가지로 기계학습이라 해도 틀린것은 아니다.
인공지능은 매우 포괄적인 개념으로 가장 많이 사용되는 대중적인 단어이다. 특정 기술 분야 뿐아니라 지능적인 요소를 가진 모든 부분에 대해 부르는 이름이다. 예를들어 게임상의 Bot이나 음성인식을 이용한 검색, 통계를 기반으로한 예측시스템들도 인공지능이라 부른다.
반면 머신러닝은 인공지능 안에서의 특정분야를 지칭하는 단어이다. 그리고 그안에 파생된 기술도 딥러닝 뿐만 아니라 다른 많은 기술도 있다. 사실 기계학습, 인공지능에 대한 연구는 예전부터 존재했지만 발전이 없었고 단지 소수에 연구원들에 의한 주제였기에 대중화 될 수 없었다고 한다. 하지만 풍부한 데이터의 확보, 컴퓨팅 성능향상, 오픈소스 라이브러리로 인해 많은 개발자들이 인공지능 연구에 참여하게 되면서부터 크게 부각이 되기 시작했다.
머신러닝
머신러닝은 데이터로부터 학습하도록 컴퓨터를 프로그래밍하는 과학이다. 스팸필터로 예를 들면 스팸필터는 스팸메일과 일반메일의 샘플을 이용해 스팸메일 구분법을 배울수 있는 머신러닝 프로그램이다.
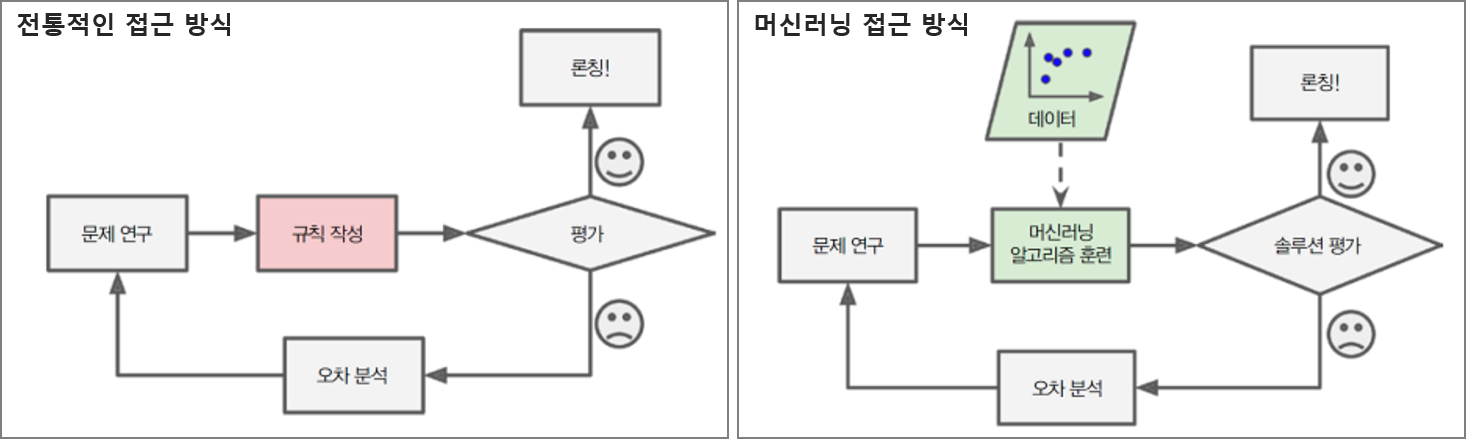
왜 머신러닝을 사용할까? 스팸 필터를 예로 전통적인 프로그래밍 기법과 비교해서 살펴보자.
스팸필터를 만들기 위해서는..
- 스팸에 어떤 단어즐이 주로 나타나는지? '4U', '신용카드', '무료' 등등
- 발견한 각 패턴을 감지하는 알고리즘을 작성하여 메일을 스팸으로 분류
- 프로그램을 테스트하고 충분한 성능이 나올 때까지 1,2단계를 반복
전통적인 접근 방법에는 문제가 단순하지 않아 규칙이 복잡해지기 때문에 유지보수가 매우 힘들다.
반면 머신러닝 기법을 이용한다면 일반 메일에 비해 스팸에 자주 나타나는 패턴을 감지하여 특정 단어나 구절이 스팸 메일을 판단하는 데 좋은 기준인지 자동으로 학습한다. 따라서 유지보수가 쉬우며 정확도가 더 높다.
만약 스팸 메일 발송자가 '4U'를 포함한 모든 메일이 차단된다는 것을 안다면 '4U' 대신 'For U'를 쓰기 시작할지도 모른다. 전통적인 프로그래밍 방식의 스팸 필터는 'For U'메일을 구분하기 위해 수정이 필요하며 단어를 바꾸면 새로운 규칙을 계속 추가해 주어야 한다.
하지만 머신러닝 기반의 스팸 필터는 사용자가 스팸으로 지정한 메일에 유동 'For U'가 자주 나타나는 것을 자동으로 인식하고 별도 작업 없이도 자동으로 이 단어를 스팸으로 분류한다.
 ori-ml
ori-ml
따라서 머신러닝 기술을 적용해서 대용량 데이터를 분석하면 겉으로는 보이지 않던 패턴을 발견할 수 있다.
머신러닝 시스템의 종류
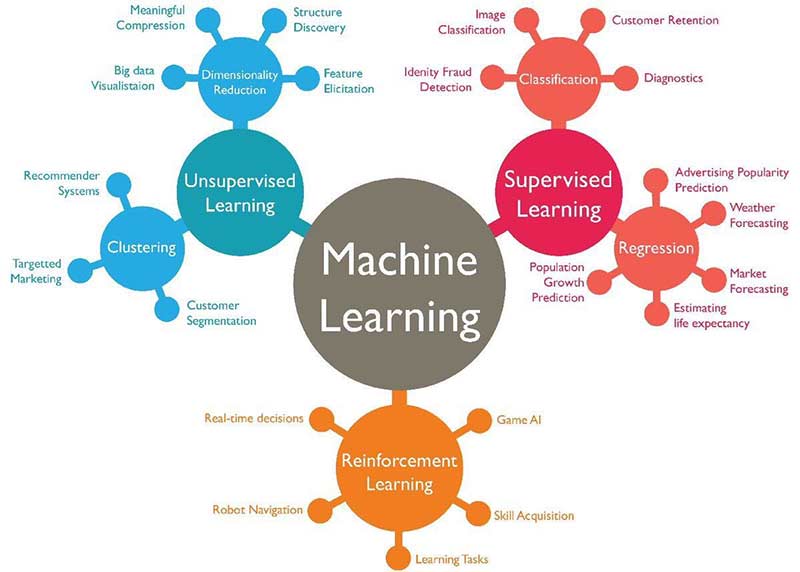
머신러닝 시스템은 크게 세가지로 구분된다.
- 지도학습(Supervised Learning),
- 비지도학습(Unsupervised Learning),
- 강화학습(Reinforcement Learning)
 ml-2
ml-2
그림 출처 : (https://www.techleer.com/articles/203-machine-learning-algorithm-backbone-of-emerging-technologies/)
각각의 어떤 특징들을 가지고 있는지 살펴보도록 하자.
지도 학습(Supervised Learning)
"지도학습은 훈련 데이터(Training Data)로부터 하나의 함수를 유추해내기 위한 기계학습의 한 방법이다." - 위키피디아
정답이 있는 데이터를 기반으로 모델을 만들어 새로운 데이터가 들어왔을때 정답을 맞추는 것이다.
지도학습은 크게 분류(Classification)과 회귀(Regression) 두가지로 분류할 수 있다.
분류 : 이진분류(예 or 아니오), 다중분류(고양이, 사자, 새..)
회귀 : 어떤 데이터들의 특징을 토대로 값을 예측(결과값은 실수, 키가 170면 몸게는?)
다음과 같이 지도학습에 사용되는 알고리즘이 있다.
- k-최근접 이웃 (k-Nearest Neighbors)
- 선형 회귀 (Linear Regression)
- 로지스틱 회귀 (Logistic Regression)
- 서포트 벡터 머신 (Support Vector Machines (SVM))
- 결정 트리 (Decision Tree) 와 랜덤 포레스트 (Random Forests)
- 신경망 Neural networks
지도학습 알고리즘에 대해서는 다음에 다루도록 하겠다.
비지도 학습(Unsupervised Learning)
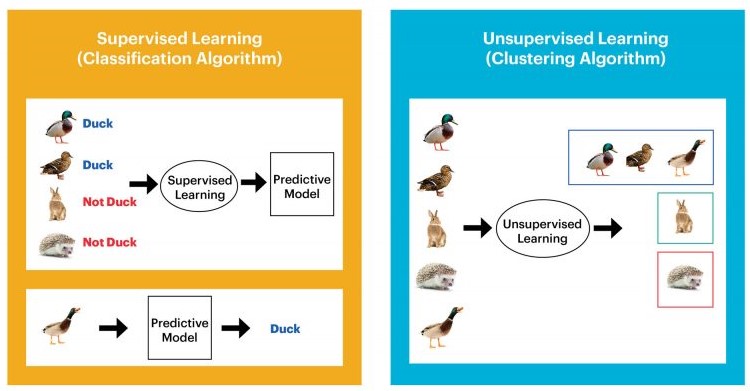
비지도 학습에 대해 이야기 하기 전에 먼저 지도 학습과 비지도 학습을 비교한 그림을 보자.
 supervised-learning-diagram
supervised-learning-diagram
"데이터가 어떻게 구성되었는지를 알아내는 문제의 범주에 속한다." - 위키피디아
지도학습과는 다르게 정답이 없는 데이터를 가지고 컴퓨터를 학습시키는 방법이다. 즉 데이터의 형태(특징?)으로 학습을 진행한다. (흔히 알고 있는 군집화..) 그리고 데이터를 이용해 컴퓨터는 스스로 어떤 관계를 찾아낸다.
비지도학습도 마찬가지로 다음과 같은 알고리즘이 있다
군집 (Clustering)
- k-평균k-Means
- 계층 군집 분석Hierarchical Cluster Analysis (HCA)
- 기댓값 최대화Expectation Maximization
시각화 (Visualization)와 차원 축소(Dimensionality reduction)
- 주성분 분석 (Principal Component Analysis (PCA))
- 커널 (kernel PCA)
- 지역적 선형 임베딩 (Locally-Linear Embedding (LLE))
연관 규칙 학습 (Association rule learning)
- 어프라이어리(Apriori)
- 이클렛(Eclat)
강화학습(Reinforcement Learning)
 reinforce
reinforce
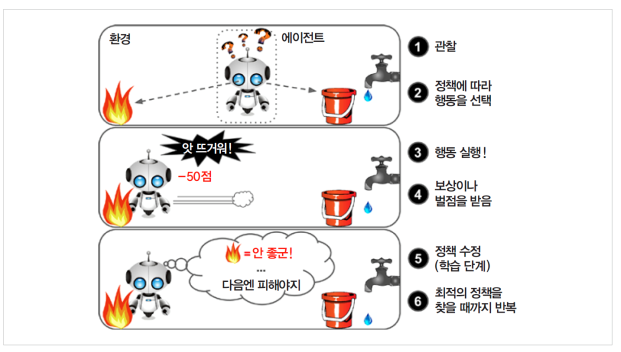
(그림 출처 : Hands-On Machine Learning 도서 - 한빛미디어)
강화학습은 상과 벌이라는 보상을 주며 상을 최대화하고 벌을 최소화 하도록 학습하는 방식이다. 주로 제어나 게임 플레이 등 상호작용을 통해서 최적의 동작을 학습해야 할 때 많이 사용된다. 데이터가 먼저 주어지는 지도학습이나 비지도학습과 달리 강화학습은 환경이 있고 에이전트가 그 환경 속에서 어떤 액션을 취하고 그 액션에 따른 어떤 보상을 얻게 되면서 학습이 진행된다. 에이전트가 보상을 최대화 하도록 하면서 학습이 진행되기 때문에 데이터 수집까지 포함하는 동적인 개념의 학습을 하게 된다. 우리의 인생으로 비유를 하자면 마치 시행 착오를 겪으며 경험이 쌓이고 경험을 토데로 옳고 그름을 판단을 수 있게 되는 것과 마찬가지다.