Kafka를 설치하고 간단하게 클러스터 환경을 구성하여 Producer 및 Consumer 테스트를 해보자.
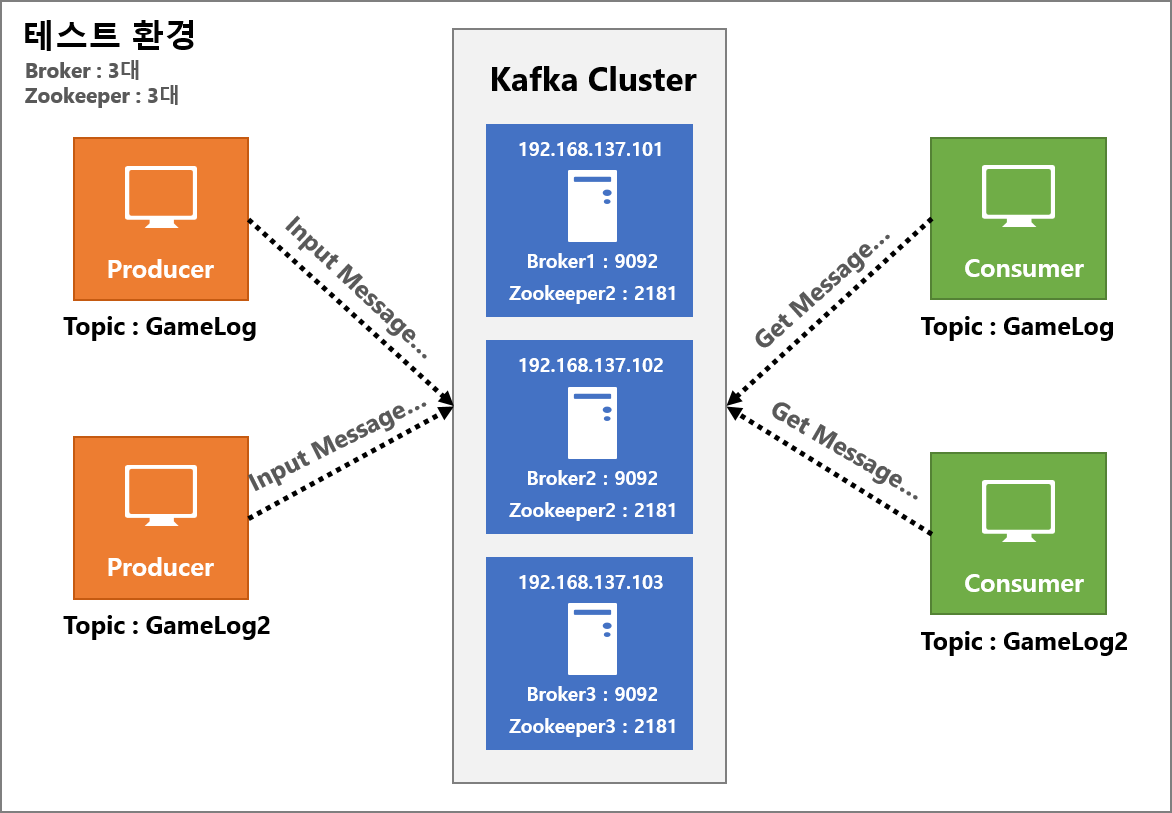
먼저 가상머신을 이용해 다음 그림과 같이 클러스터 환경을 구성하여 테스트를 진행할 것이다.
 img
img
이 글에서는 3대의 서버를 생성하였지만 1대의 서버로 포트를 다르게 하여 구성할 수도 있다. 또한 Kafka와 Zookeeper서버를 동일한 장비에 구축하였지만 실무에서는 별도로 구축하는 것이 좋다.
Kafka 다운로드 및 설치
다운로드(각 버전에 대해서는 https://kafka.apache.org/downloads를 참고하자.)
$ wget http://apache.mirror.cdnetworks.com/kafka/2.1.0/kafka_2.11-2.1.0.tgz압축해제 및 경로이동
$ tar -zxvf kafka_2.11-2.1.0.tgz
$ cd kafka_2.11-2.1.0Kafka의 동작은 Zookeeper에 의해 관리가 되기 때문에 Zookeeper 없이는 Kafka를 구동할 수 없다. 이 때문에 Kafka를 다운로드 하면 Zookeeper도 함께 들어있다. 물론 별도로 최신버전의 Zookeeper를 다운받아 사용해도 되지만, Kafka에 들어있는 Zookeeper는 Kafka버전과 잘 동작하는 검증된 버전이므로 패키지 안에 있는 Zookeeper의 사용을 권장한다.
Zookeeper 설정
각 인스턴스에 설치된 Kafka의 config/zookeeper.properties 파일은 하나의 Zookeeper를 실행하는데 쓰이는 설정 파일이다. 이 말은 zookeeper1.properties, zookeeper2.properties, zookeeper3.properties 이런식으로 여러개의 설정파일을 만들고 하나의 장비에서 다중으로 실행할 수 있다는 의미이다. 설정파일을 다음과 같이 3대의 서버에 동일하게 추가하자.
$ vi config/zookeeper.properties# the directory where the snapshot is stored.
dataDir=**/tmp/zookeeper**
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections
# since this is a non-production config
maxClientCnxns=0
initLimit=5
syncLimmit=2
server.1=192.168.137.101:2888:3888
server.2=192.168.137.102:2888:3888
server.3=192.168.137.103:2888:3888새로 추가한 설정값은 클러스터를 구성하는데 필요한 설정 값들안데 여기서 주의할 점은 모든 Zookeeper 서버들은 동일한 변수 값을 가지고 있어야 한다.
initLimit
팔로워가 리더와 초기에 연결하는 시간에 대한 타임아웃
syncLimit
팔로워가 리더와 동기화 하는데에 대한 타임아웃. 즉 이 틱 시간안에 팔로워가 리더와 동기화가 되지 않는다면 제거 된다.
이 두값은 dafault 기본값이 없기 때문에 반드시 설정해야 하는 값이다.
그리고 server.1,2,3의 숫자는 인스턴스 ID이다. ID는 dataDir=/tmp/zookeeper 폴더에 myid파일에 명시가 되어야 한다.
/tmp/zookeeper 디렉토리가 없다면 생성하고 myid 파일을 생성하여 각각 서버의 고유 ID값을 부여해야 한다.
(그 외 자세한 설정정보를 알고 싶다면 주키퍼 가이드문서를 참고하자.)
1 서버 (192.168.137.101)
$ mkdir /tmp/zookeeper
$ echo 1 > /tmp/zookeeper/myid2 서버 (192.168.137.102)
$ mkdir /tmp/zookeeper
$ echo 2 > /tmp/zookeeper/myid3 서버 (192.168.137.103)
$ mkdir /tmp/zookeeper
$ echo 3 > /tmp/zookeeper/myid이제 Zookeeper를 구동하기 위한 설정은 끝~
Kafka 설정
Kafka의 config/server.properties 파일은 하나의 Kafka를 실행하는데 쓰이는 설정 파일이다. Zookeeper와 마찬가지로 여러개의 설정파일을 만들고 다중 실행을 할 수 있다.
설정파일 config/server.properties에 3대 서버 각 환경에 맞는 정보를 입력해 준다.
$ vi config/server.properties1 서버 (192.168.137.101)
broker.id=1
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://**192.168.137.101**:9092
zookeeper.connect=192.168.137.101:2181, 192.168.137.102:2181, 192.168.137.103:21812 서버 (192.168.137.102)
broker.id=2
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://**192.168.137.102**:9092
zookeeper.connect=192.168.137.101:2181, 192.168.137.102:2181, 192.168.137.103:21813 서버 (192.168.137.103)
broker.id=3
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://**192.168.137.103**:9092
zookeeper.connect=192.168.137.101:2181, 192.168.137.102:2181, 192.168.137.103:2181별도 파일(/tmp/zookeeper/myid)에 인스턴스 ID를 명시해야 하는 Zookeeper와는 달리 Kafka는 설정파일안에 broker.id라는 항목이 있다.
그리고 zookeeper.connet라는 항목에는 Zookeeper인스턴스들의 정보를 입력해준다.
Kafka를 구동하기 위한 설정은 끝났다. 클러스터 구성을 위한 인스턴스들의 정보를 입력해 주는것이 거의 대부분의 설정이다.
그외 설정 파일에 대한 상세한 내용은 공식 홈페이지의 Broker Configs를 참고하길 바란다. default설정값을 확인하고 변경하고자 하는 값들은 설정파일에 명시를 해주면 된다.
Zookeeper 및 Kafka 서버 구동
Kafka를 구동하기 위해 먼저 Zookeeper를 구동 한다음 이후 Kafka를 구동해야 한다.
$ bin/zookeeper-server-start.sh config/zookeeper.properties
$ bin/kafka-server-start.sh config/server.properties3대의 서버에 Zookeeper와 Kafka가 정상적으로 구동이 되었다면 다음과 같이 starting 메시지를 확인할 수 있을 것이다.
*starting (kafka.server.KafkaServer)
이제 기본적인 클러스터 환경을 구성하고 서버를 구동시켰다.
Kafka에서는 bin폴더 아래 제공되는 스크립트 파일을 이용해 Topic을 관리하고 Producer,Consumer를 테스트 해볼수 있다.
기본적인 몇가지 스크립트 명령을 이용해 Topic을 생성해 보고 Producer 메시지를 저장하고 Consumer 메시지를 읽어오는것을 확인해 보도록 하자.
Topic 관리
1. Topic생성
GameLog, GameLog2, GameLog3 세개의 Topic을 생성해보자.(replication-factor:3, partitions : 1)
$ bin/kafka-topics.sh --create --zookeeper 192.168.137.101:2181, 192.168.137.102:2181, 192.168.137.103:2181 --replication-factor 3 --partitions 1 --topic GameLog
$ bin/kafka-topics.sh --create --zookeeper 192.168.137.101:2181, 192.168.137.102:2181, 192.168.137.103:2181 --replication-factor 3 --partitions 1 --topic GameLog2
$ bin/kafka-topics.sh --create --zookeeper 192.168.137.101:2181, 192.168.137.102:2181, 192.168.137.103:2181 --replication-factor 3 --partitions 1 --topic GameLog3출력 Created topic "GameLog"
2. Topic 리스트 확인
$ bin/kafka-topics.sh --list --zookeeper 192.168.137.101:2181, 192.168.137.102:2181, 192.168.0.103:2181출력 GameLog GameLog2 GameLog3
3. Topic 삭제
$ bin/kafka-topics.sh --delete --zookeeper 192.168.137.101:2181, 192.168.137.102:2181, 192.168.137.103:2181 --topic GameLog3출력 Topic GameLog3 is marked for deletion
4. Topic 상세 정보 확인
$ bin/kafka-topics.sh --describe --zookeeper 192.168.137.101:2181, 192.168.137.102:2181, 192.168.137.103:2181출력 PartitionCount:1 ReplicationFactor:3..
토픽을 생성했으면 해당 토픽에 메시지를 생산하고 소비하는것을 직접 확인해보자.
메시지 생산 및 소비
1.Producer 메시지 생산하기
$ bin/kafka-console-producer.sh --broker-list 192.168.137.101:9092,192.168.137.102:9092,192.168.137.103:9092 --topic GameLog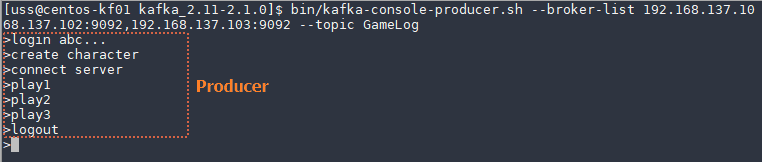 img
img
2.Consumer 메시지 소비하기
$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.137.101:9092,192.168.137.102:9092,192.168.137.103:9092 --topic GameLog --from-beginning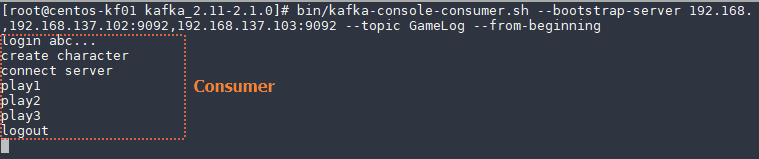 img
img
from-beginning 옵션은 해당 topic의 맨 처음 메시지부터 소비하겠다는 의미이다.
그림에서 보는 것과 같이 Producer에서 메시지를 입력하면 Consumer에서 해당 메시지를 읽어오는 것을 확인 할 수 있다.
지금까지 Kafka 클러스터를 직접 구축하여 메시지 생산하고 소비하는 것을 간단하게 해보았다.